고가용성이란
HA(High Availability) 아키텍처는 말 그대로 고가용성 아키텍처를 의미합니다. 여기서 가용성이란 시스템이 정상적으로 사용가능한 정도를 의미하는 말입니다. 즉, 전체 시간 중 시스템이 다운되지 않고 정상적으로 사용가능한 시간의 비율입니다.
현대 서비스에서 가용성은 직접적인 매출과도 관련된 중요한 속성입니다. 예를 들어 시간 당 1억씩 버는 쇼핑몰의 경우 1시간 동안 장애가 발생하면 1억의 손실이 발생하게 됩니다. 또한 할인 이벤트와 같이 서비스에서 중요한 순간에 장애가 발생하면 매출뿐만이 아니라 사용자의 경험에 안 좋은 영향을 주어 기회비용까지 잃게 됩니다. 즉, 브랜드 신뢰도와도 연관된 성질입니다.
이런 가용성을 백분율로 표시해놓은 수치가 있습니다. 아래 표는 위키피디아에서 가져왔습니다.
가용성 % 한 해 중 다운타임[주 1] 분기 중 다운타임 1개월 중 다운타임 1주 중 다운타임 1일(24시간) 중 다운타임
| 90% ("one nine") | 36.53 일 | 9.13 일 | 73.05 시간 | 16.80 시간 | 2.40 시간 |
| 95% ("one and a half nines") | 18.26 일 | 4.56 일 | 36.53 시간 | 8.40 시간 | 1.20 시간 |
| 97% | 10.96 일 | 2.74 일 | 21.92 시간 | 5.04 시간 | 43.20 분 |
| 98% | 7.31 일 | 43.86 시간 | 14.61 시간 | 3.36 시간 | 28.80 분 |
| 99% ("two nines") | 3.65 일 | 21.9 시간 | 7.31 시간 | 1.68 시간 | 14.40 분 |
| 99.5% ("two and a half nines") | 1.83 일 | 10.98 시간 | 3.65 시간 | 50.40 분 | 7.20 분 |
| 99.8% | 17.53 시간 | 4.38 시간 | 87.66 분 | 20.16 분 | 2.88 분 |
| 99.9% ("three nines") | 8.77 시간 | 2.19 시간 | 43.83 분 | 10.08 분 | 1.44 분 |
| 99.95% ("three and a half nines") | 4.38 시간 | 65.7 분 | 21.92 분 | 5.04 분 | 43.20 초 |
| 99.99% ("four nines") | 52.60 분 | 13.15 분 | 4.38 분 | 1.01 분 | 8.64 초 |
| 99.995% ("four and a half nines") | 26.30 분 | 6.57 분 | 2.19 분 | 30.24 초 | 4.32 초 |
| 99.999% ("five nines") | 5.26 분 | 1.31 분 | 26.30 초 | 6.05 초 | 864.00 밀리초 |
| 99.9999% ("six nines") | 31.56 초 | 7.89 초 | 2.63 초 | 604.80 밀리초 | 86.40 밀리초 |
| 99.99999% ("seven nines") | 3.16 초 | 0.79 초 | 262.98 밀리초 | 60.48 밀리초 | 8.64 밀리초 |
| 99.999999% ("eight nines") | 315.58 밀리초 | 78.89 밀리초 | 26.30 밀리초 | 6.05 밀리초 | 864.00 마이크로초 |
| 99.9999999% ("nine nines") | 31.56 밀리초 | 7.89 밀리초 | 2.63 밀리초 | 604.80 마이크로초 | 86.40 마이크로초 |
HA 아키텍처의 원칙
고가용성을 달성하기 위해서는 어떻게 해야할까요? 고가용성을 이루기 위해 고려해야할 몇 가지 원칙들이 있습니다.
첫번째는 SPOF(Single Point Of Failure)를 제거하는 것입니다. SPOF란 단일 장애점을 의미합니다. 즉 전체 시스템에서 어느 한 부분의 장애로 인해 전체 시스템이 멈추게 되는 부분을 의미합니다.
흔히 토이 프로젝트를 할 때의 아키텍처를 생각해봅시다. 보통 서버 1대, DB 1대를 구성합니다.
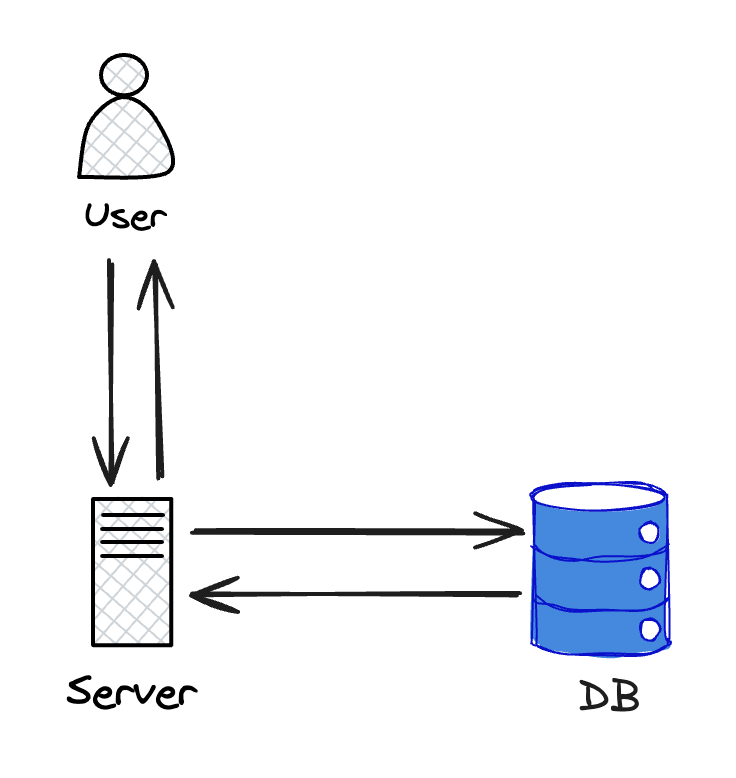
여기서 만약 서버에 장애가 발생하면 어떻게 될까요? 또는 DB에 장애가 발생하면 어떻게 될까요?
다른 한 곳이 멀쩡해도 장애가 발생한 부분으로 인해 사용자는 서비스를 사용할 수 없을 겁니다. 그렇게 되면 고가용성을 지원해준다고 말하기 힘들겁니다. 이렇게 한 곳의 장애가 전체 시스템의 중단으로 작동하지 않도록 해주기 위해 보통 다중화를 해줍니다.

이렇게 서버나 DB를 다중화하면 서버나 DB 중 1대가 장애가 발생해도 다른 서버나 DB에서 요청을 처리해주고 장애가 난 서버나 DB는 조치를 취해 다시 살린 뒤 요청을 받도록 하면 고가용성을 지원할 수 있습니다.(물론 위의 그림에서도 로드 밸런서가 SPOF 지점으로 보이긴 하네요. 실무에서는 AWS의 ALB를 활용하거나 실제로 로드 밸런서도 다중화를 하여 SPOF가 되지 않도록 해줍니다.)
위에서 주의 깊게 봐야될 부분은 DB의 다중화 입니다. 일반적으로 서버는 Stateless하게 구현합니다. Stateless는 간단히 상태를 보관하지 않는다고 이해하면 될 것 같습니다. 이는 한 명의 사용자의 요청에 대한 정보를 서버가 보관하지 않도록 한다는 뜻입니다. 즉, 요청을 처리할 때 이전 요청의 정보를 가지고 있어야 처리가 가능한 부분이 존재하지 않습니다. 그렇기에 한 사용자의 요청이 처음에 1번 서버에 왔다가 다음 요청은 2번 서버에 왔다고 하더라도 전혀 문제되지 않습니다. 하지만 DB는 데이터를 보관하고 있기 때문에 Stateful한 시스템입니다. 만약 한 사용자가 특정 정보를 저장해달라는 요청이 1번 DB에 오고 다음에 이전에 요청한 정보를 수정해달라는 요청이 2번 DB에 오게되면 2번 DB에는 해당 데이터가 없기 때문에 해당 요청을 처리할 수 없습니다. 그렇기에 DB의 경우에는 복제(Replication)를 통해 데이터의 일관성을 보장해주어야 다중화를 수행할 수 있습니다.
두번째는 백업 및 지리적 분산입니다. 우리는 서비스를 구현할 때 이상적으로 장애없이 서비스가 동작할 거라고 생각하지만 현실에서는 예상치 못한 수많은 장애 상황이 발생합니다. 심지어 하필 서비스를 구축해놓은 곳에 천재지변이 발생할 수도 있습니다. 이런 상황을 대비하여 백업 및 복구 프로세스를 구축하여 데이터가 유실되었더라도 빠르게 복구할 수 있는 시스템을 갖추는 것이 중요합니다.
여기서 중요한 점은 지리적 분산입니다. 백업 시스템을 잘 구축했더라도 백업본을 기존 서버와 같은 곳에 위치시키면 천재지변이 발생할 경우 백업본도 같이 망가질 겁니다. 그렇다면 백업의 이점을 살릴 수 없을 겁니다. 그렇기에 백업본을 한 곳에 두는 것이 아닌 완전히 물리적으로 다른 곳에 분산하여 천재지변과 같은 영향을 공유하지 않도록 해야합니다.
이런 지리적 분산은 단순히 백업본에만 국한된 것이 아닙니다. 서버의 경우에도 지리적 분산이 중요합니다. 다중화를 했더라도 전부 망가지면 시스템이 동작하지 않을 것이기 때문입니다.
세번째는 자동 장애 감지 및 복구입니다. 이는 시스템의 장애를 사람이 직접 24시간 모니터링 하면서 대처할 수 없기 때문입니다. 그렇기에 시스템 스스로 장애를 감지하고 대처하여 복구할 수 있도록 설계해야 합니다. 보통 Health Check 매커니즘을 통해 각 구성요소의 상태를 점검하면서 문제가 발생하면 이를 감지하고 자동으로 다른 정상적인 서버로 우회시키거나 새로운 서버를 띄웁니다. 여기서 Fail Over와 Fail Back이라는 단어가 나옵니다. Fail Over는 위에서 설명한 장애가 발생했을 시 다른 서버로 우회시키는 것을 의미합니다. Fail Back은 장애가 발생한 서버를 장애가 발생하기 전의 상태로 복구시키는 것을 의미합니다.
트레이드 오프
지금까지 고가용성의 필요성과 고가용성을 달성하기 위한 방법들을 설명했습니다. 하지만 절대적인 정답은 없듯이 고가용성을 달성하는 것이 무조건 좋은 것만은 아니고 단점도 존재합니다. 대표적으로 복잡성과 비용이 있습니다.
위의 다중화 아키텍처만 봐도 흔히 토이 프로젝트에서 사용하는 아키텍처보다 훨씬 복잡합니다. 특히 DB의 경우 Replication도 구축해 주어야 합니다. 단순히 토이 프로젝트라기엔 너무 과할 수도 있습니다.
또한 비용도 배로 증가합니다. 단순히 계산해도 서버 1대, DB 1대일 때에 비해 서버 3대, DB 3대로 다중화를 하게 되면 비용이 3배로 늘어나게 됩니다. 부자가 아닌 한 토이 프로젝트에 이 정도의 비용을 투자하는 것은 부담스럽습니다. 대부분의 토이프로젝트의 경우 유저나 수익 모델이 부족해 수익을 내기도 힘든데 말이죠.
그렇기에 무조건 고가용성을 고집하는 것이 아닌 비즈니스 요구사항과 현실적 제약 사이에서 최적의 균형점을 찾는 것이 중요할 것입니다. 만약 고가용성을 달성하는데 1달에 100만원의 추가비용이 나가지만 장애가 발생하면 5000만원의 손실이 발생하면 추가비용을 내서라도 고가용성을 달성하는 것이 중요할 것 입니다. 하지만 대부분의 토이 프로젝트에선...?
마무리
지금까지 HA 아키텍처를 주제로 글을 작성했습니다. 현대의 서비스에선 특히 대규모 서비스일수록 고가용성은 매우 중요한 요소입니다. 그렇기에 많은 회사에서 이런 고가용성을 보장하기 위해 많은 노력을 기울이고 있고 많은 기업 블로그에서도 관련 내용들을 소개하고 있습니다. 이런 여러 자료들을 바탕으로 공부하면서 실제로 프로젝트에 적용해보면 엔지니어로서 큰 성장을 이룰 수 있을 것입니다.
'System Architecture' 카테고리의 다른 글
| 메시징 패턴: Pub-Sub, Queues, and Event Streams (1) | 2025.06.05 |
|---|---|
| 엔지니어링의 트레이드오프: 실제 환경에서의 최종적 일관성 (Eventual Consistency) (0) | 2025.05.29 |
| Slack은 어떻게 하루 수십억 개의 메시지를 처리할까 (0) | 2025.05.22 |
| 마이크로서비스 설계 패턴 핵심 요약 (0) | 2025.05.10 |
| 당신이 알아야 할 시스템 설계의 핵심 개념 20가지 - 2. 캐싱 (0) | 2025.05.01 |