
일반적인 시스템 설계
일반적으로 개인이나 동아리 or 부트캠프에서 프로젝트를 진행하게 되면 서버 1대, DB 1대를 둔 아래와 같은 설계를 따릅니다.
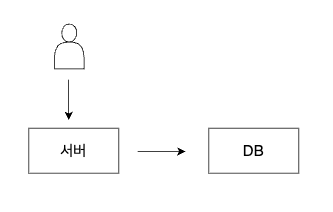
대부분의 개인이나 팀으로 이뤄지는 프로젝트는 많은 트래픽이 발생하지 않습니다. 1대의 서버로도 충분히 감당할 수 있을 정도로요.
하지만 갑자기 프로젝트가 알려지면서 트래픽이 몰리면 어떻게 될까요? 각 서버는 성능에 따라 처리할 수 있는 트래픽의 양이 한정되어 있습니다. 그래서 과도한 트래픽을 받게 되면 서버에 장애가 발생할 수 있습니다.
만약 복잡한 것이 싫다면 이런 상황에서 서버의 성능을 올리는 것으로 간단하게 해결할 수 있습니다. 더 좋은 CPU나 RAM을 가진 서버로 업그레이드를 하면 더 많은 트래픽을 처리할 수 있습니다. 이를 Scale Up이라고 부릅니다. 하지만 이 방법은 결국 한계점이 존재합니다. 아무리 좋은 서버여도 그 한계가 존재하기 때문입니다. 또한 위의 설계에서 서버와 DB 중 1곳에서만 장애가 발생해도 전체 서비스가 중단되게 됩니다. 이렇게 시스템의 구성 요소 중 한 곳에서 장애가 발생하면 전체 시스템이 중단되는 지점을 SPOF라고 부릅니다. 개발자는 이런 SPOF를 방지하기 위한 시스템을 설계해야 합니다.
로드 밸런싱(Load Balancing)
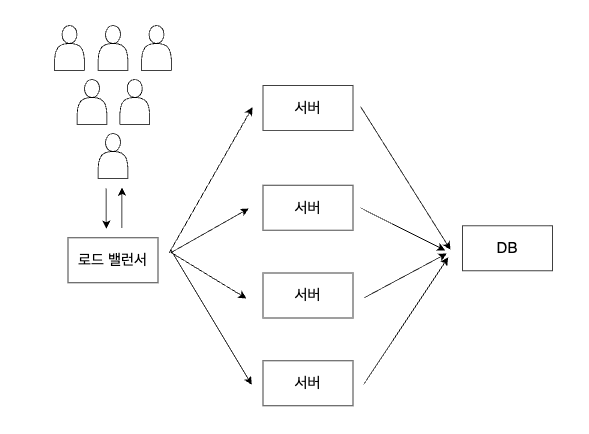
Scale Up과는 다른 방법으로 Scale Out이 있습니다. 이는 서버의 개수를 늘리는 방식으로 트래픽 성능의 처리를 높이는 방법입니다. 이때 Scale Up과 Scale Out을 통틀어 Scalability라고 합니다. Scale Out을 적용하여 각 서버로 균등하게 트래픽을 할당하는 방식이 로드 밸런싱입니다. 즉, 로드 밸런싱은 애플리케이션을 지원하는 리소스 풀에 들어오는 네트워크 트래픽(들어오는 요청)을 균등하게 분산하는 것을 의미합니다. 간단히 비유하면 은행에서 고객들(네트워크 트래픽)을 대기 번호표를 뽑게 한 뒤 여러개의 창구(서버)에서 각 고객의 업무를 처리한다고 볼 수 있을 것 같습니다.
이렇게 로드 밸런싱을 하게 되면 일부 서버에서 장애가 발생해도 설정을 통해 해당 서버로는 요청을 보내지 않고 서버를 추가할 때도 설정에 추가해주면 되기 때문에 SPOF를 방지할 수 있습니다.
이렇게 로드 밸런싱을 수행하는 하드웨어나 소프트웨어를 로드 밸런서라고 부릅니다. 로드 밸런서에는 여러 종류가 존재하고 로드 밸런싱을 수행하는 알고리즘도 여러개가 존재합니다.
복제(Replication)
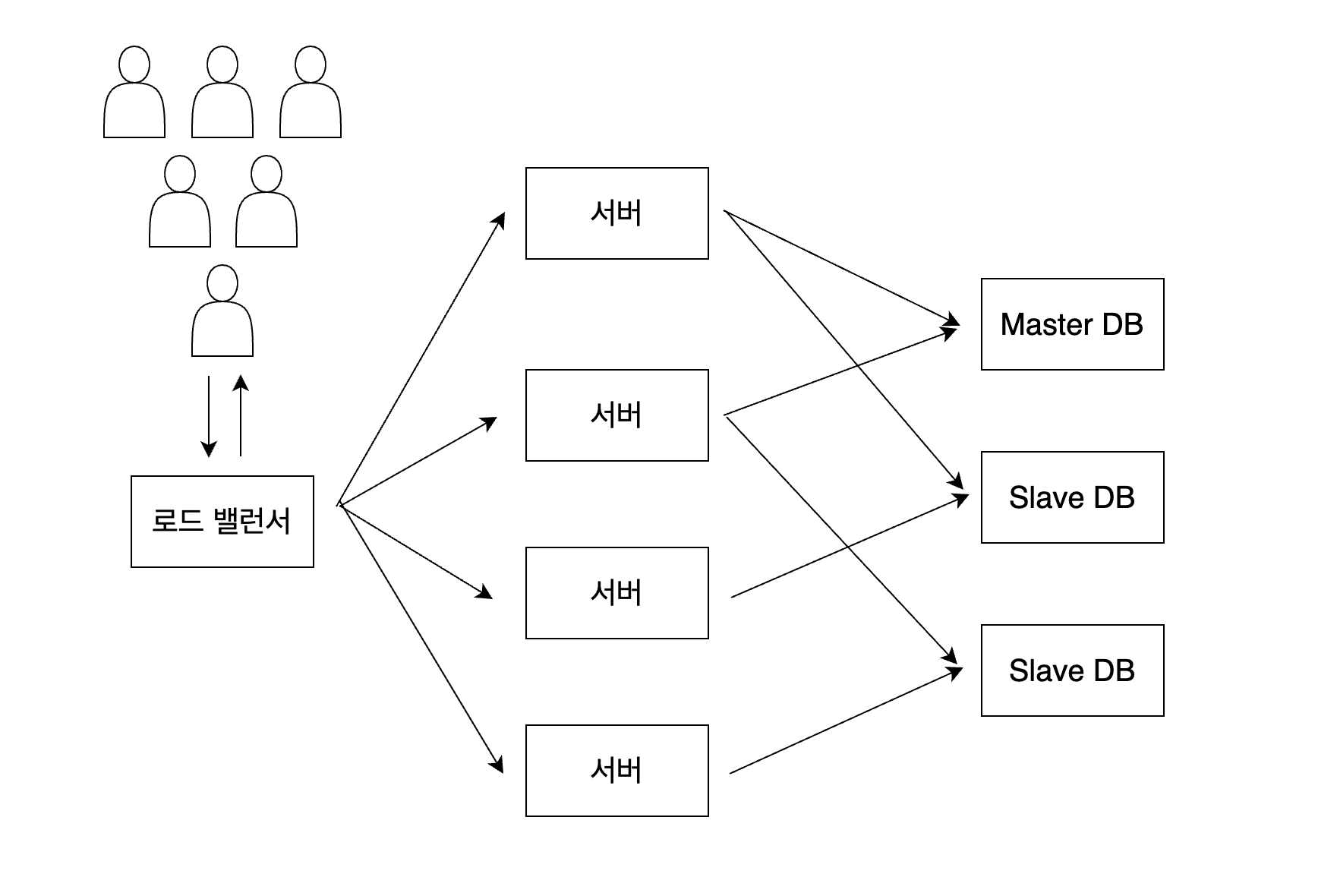
로드 밸런싱을 통해 서버는 SPOF를 방지했지만 여전히 DB는 SPOF 지점으로 남아있습니다. 하지만 서버와 달리 DB는 개수만 늘린다고 끝나지 않습니다. DB의 개수를 늘려도 각 DB가 서로 다른 데이터를 가지고 있으면 안 되기 때문입니다. 그렇기에 Replication이 필요합니다. DB끼리 데이터를 복사해 동일한 데이터를 가지고 있도록 하는 방법입니다. 복제 방식에는 여러 방식이 존재하지만 보통은 Master - Slave 관계를 설정하여 Master DB에만 쓰기가 가능하도록 하고 Master DB의 데이터를 여러 Slave DB에 복제한 뒤 Slave DB의 데이터를 읽는 방식을 사용합니다. 만약 Slave DB 중 1대에 장애가 발생하면 다른 Slave DB에서 데이터를 읽으면 됩니다. 만약 Master DB에 장애가 발생하면 Slave DB 중 하나를 Master DB로 승격시킨 뒤 사용하면 됩니다. 이렇게 DB도 다중화하여 SPOF를 방지할 수 있습니다. 이런 식으로 각 구성 요소들의 다중화를 통해 SPOF를 방지하는 것이 장애 허용성(Fault Tolerance)입니다.
CAP 이론(CAP Theorem)
DB 다중화를 설계할 때는 CAP 이론을 이해해야 합니다. CAP 이론은 일관성(Consistency), 가용성(Availability), 파티션 감내성(Partition Tolerance) 세 가지를 모두 만족하는 분산 시스템을 설계하는 것은 불가능하다는 내용입니다.
- 일관성 : 분산 시스템에서 언제나 모든 DB가 동일한 데이터를 가지고 있어야 된다는 뜻입니다.
- 가용성 : 분산 시스템에서 일부 DB에 장애가 발생하더라도 언제나 응답이 가능해야 한다는 뜻입니다.
- 파티션 감내성 : 여기서 파티션은 DB 사이의 통신 장애가 발생한 것을 의미합니다. 즉, 파티션 감내성은 DB 사이에 통신 장애가 발생했더라도 시스템은 계속 동작해야 한다는 것을 의미합니다.
이때 분산 시스템에서 통신 장애는 100% 예방할 수 없습니다. 무조건 발생할 수 있기 때문에 파티션 감내성은 무조건 가지고 있어야 합니다. 이제 통신 장애가 발생한 상황을 가정해보겠습니다.

DB 1, DB 2, DB 3가 있을 때 DB 3에서 장애가 발생한 상황을 나타낸 그림입니다. 이런 상황에서는 DB 3는 DB 1과 DB 2의 데이터 복제본을 받지 못합니다. 또한 DB 3에 저장되어 있지만 DB 1, DB 2에 전달하지 못한 데이터가 있을 수도 있습니다. 이런 상황에서 만약 일관성을 택하게 된다면 데이터 불일치 문제를 피하기 위해 다른 DB 1, DB 2에도 쓰기 작업을 중단해야 합니다. 이는 가용성을 해치게 됩니다. 그렇다고 가용성을 택하게 된다면 DB 1,2와 DB 3의 일관성을 해치게 됩니다. 그렇기에 일관성과 가용성 중 하나는 포기해야 합니다.
금융권과 같이 일관성이 중요한 분야를 제외한 서비스에서는 일반적으로 가용성을 선택합니다. 그렇기에 각 DB 들이 항상 최신 데이터를 가지고 있지 못할 수 있습니다. 하지만 언젠가는 복제가 되어 최신 결과를 받을 수 있습니다. 이렇게 데이터 갱신 결과가 결국에는 모든 DB에 동기화되는 모델이 최종 일관성(Eventual Consistency)입니다.
DB 조회 성능 향상
이제 SPOF를 방지하여 장애 상황에서도 서비스가 동작되도록 설계했습니다. 최소한의 안전은 확보했으니 이제는 클라이언트의 사용성을 개선시키기 위해 응답 시간을 단축시키면 좋을 것 같습니다. 그래서 서비스가 동작할 때 어떤 부분에서 리소스를 많이 잡아먹는 지 확인해봤더니 서버에서 DB의 데이터를 읽을 때 오랜 시간이 걸린다는 것을 확인했습니다. 그래서 DB 읽기 성능을 향상시키려고 합니다. 이때 보통은 인덱싱(DB Indexing)을 사용합니다. 인덱싱은 DB의 컬럼에 인덱스를 설정하는 작업입니다. 여기서 인덱스는 책의 목차나 색인이라고 생각하면 좋을 것 같습니다. 책에서 원하는 정보가 있을 때 무작정 처음부터 끝까지 다 살펴보는 것보다 목차나 색인을 활용하여 정보를 찾으면 더 빠르게 찾을 수 있는 것과 같이 DB의 데이터를 읽을 때 인덱스를 활용하면 더 빠르게 원하는 데이터를 찾을 수 있습니다.
인덱스는 DB의 특정 컬럼으로 설정할 수 있는데 인덱스로 설정할 컬럼은 사용자의 요청에 따른 SQL 쿼리를 분석하여 설정하게 됩니다. 만약 무분별하게 인덱싱을 설정하게 되면 쓰기 성능이 저하될 수 있으니 자주 사용되는 컬럼만 인덱스로 설정해야 합니다.
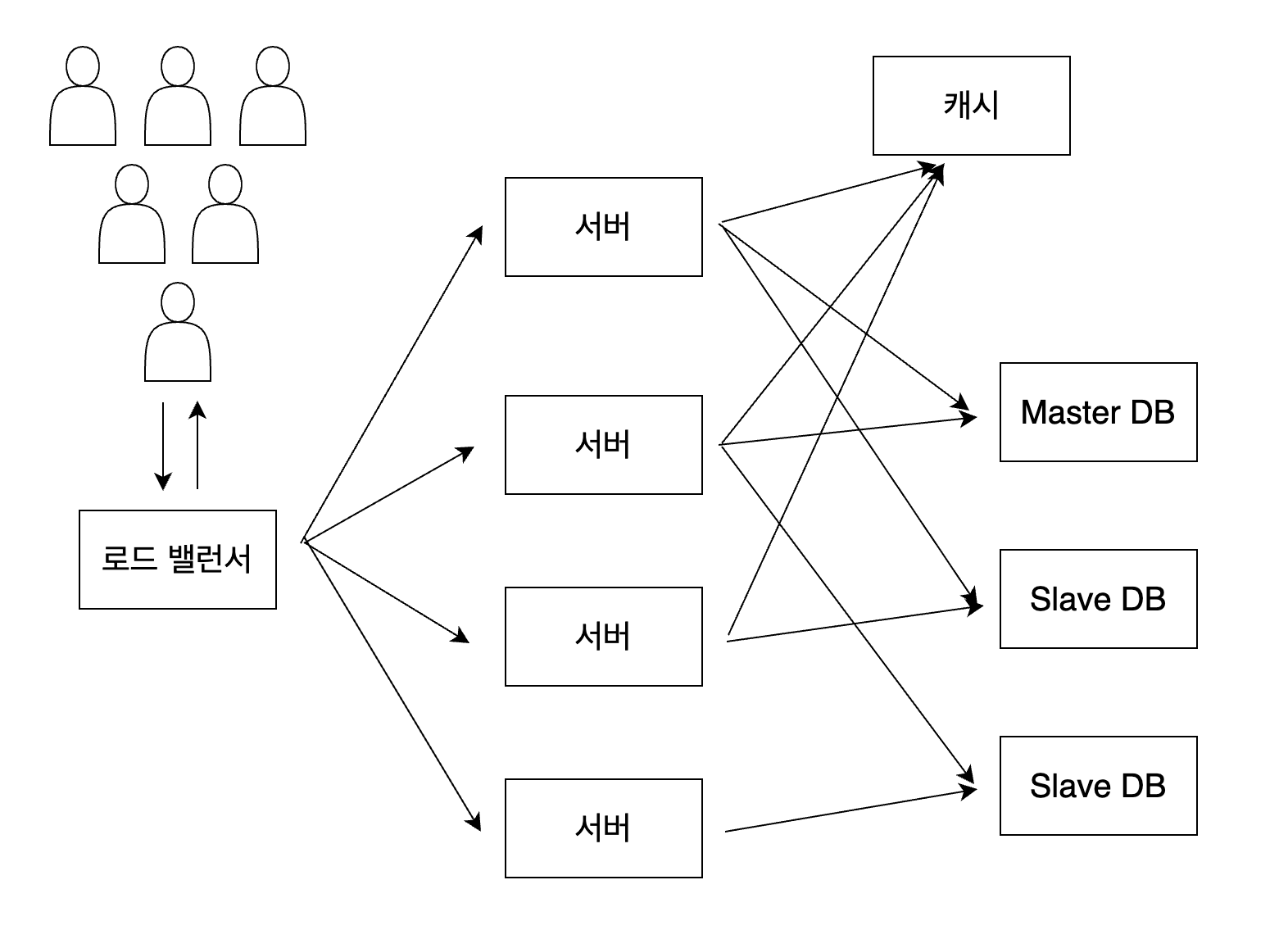
또한 읽기 성능을 향상시키기 위해 캐싱(Caching)을 사용할 수 있습니다. 캐싱은 자주 사용되는 데이터의 복사본을 캐시 또는 임시 저장 위치에 저장하여 빠르게 접근할 수 있도록 하는 프로세스를 의미합니다. 보통은 Redis를 활용하여 캐싱합니다. 이때 캐시와 DB 사이의 정합성을 유지하는 것에 신경써줘야 합니다.
CDN
서비스가 점점 잘 되서 이제 해외에서도 서비스를 하게 되었습니다. 만약 서버가 국내에만 있게 되면 해외 유저의 요청은 지리적 거리로 인해 응답 시간이 매우 길어질 겁니다. 그래서 해외에도 서비스를 하게되면 보통 CDN을 사용하게 됩니다. CDN은 정적 콘텐츠를 캐싱하는 지리적으로 분산된 서버의 네트워크입니다. 동적 콘텐츠도 캐싱이 가능하다고 하는데 이 글에선 정적 콘텐츠의 캐싱만 다루겠습니다. CDN을 사용하게 되면 특정 사용자의 요청은 그 사용자에게 가장 가까운 CDN이 처리하게 됩니다. 이때 CDN에 해당 파일이 존재하면 바로 해당 파일을 반환하고 CDN에 없으면 원본 서버에서 해당 파일을 가져와 CDN에 저장한 뒤 이후의 요청에선 CDN에서 해당 파일을 반환하게 됩니다.
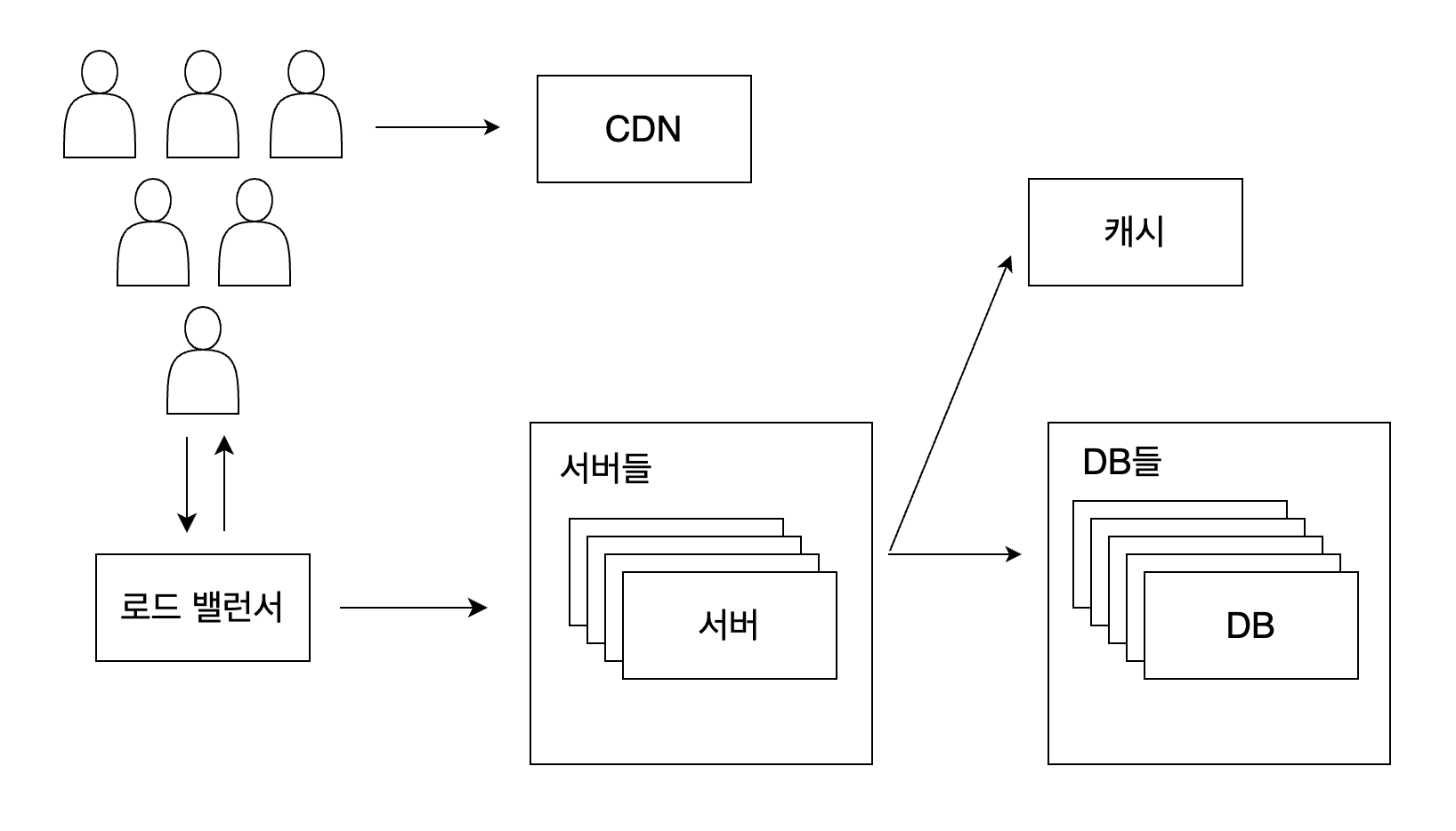
DB 분할
서비스가 너무 잘되서 DB의 테이블에 수많은 데이터가 쌓였습니다. 그러면 하나의 DB에서 그 데이터의 양을 감당할 수 없게 됩니다. 또한 쿼리 속도도 느려지게 됩니다. 이때 사용하는 방법 중 하나가 샤딩(Database Sharding)입니다. 샤딩은 데이터베이스를 키값이나 특정 범위를 기준으로 분할하는 기술입니다. 이렇게 분할된 각 단위를 샤드라고 부릅니다. 모든 샤드는 같은 스키마를 사용하지만 각 샤드에 저장된 데이터 사이에는 중복이 없습니다.
샤딩을 할 때 주의할 점은 샤딩 키를 어떻게 정할지 입니다. 샤딩키를 잘못 지정하여 하나의 샤드에 과도한 데이터가 저장되면 샤딩을 하는 의미가 없어집니다. 또한 샤딩을 하게 되면 여러 샤드에 걸친 데이터를 조인하기가 힘들어집니다. 이런 사항들에 주의하여 샤딩 키를 설정해야 합니다.
추가적으로 파티셔닝(Partitioning)도 샤딩과 비슷합니다. 차이점은 샤딩은 테이블을 여러 개의 DB로 분할하지만 파티셔닝은 하나의 DB에서 데이터를 논리적으로 분할하는 방식입니다. 그래서 테이블에 데이터가 많아지면 파티셔닝을 통해 읽는 범위를 줄여 성능을 향상시킬 수 있지만 DB 자체는 한개만 사용하기 때문에 완전한 해결은 힘듭니다.
안정 해시(Consistent Hashing)
샤딩과 같이 데이터를 분산시켜 저장하다가 만약 데이터가 더 증가해 하나의 샤드에서 감당하기 어려워지는 등의 상황으로 샤드 키를 변경하게 되면 데이터를 재배치해야 합니다. 이때 재배치 해야할 데이터가 많을 수록 소요 시간은 증가할 겁니다. 이때 재배치 해야할 데이터를 줄이기 위해 안정 해시를 사용합니다. 안정 해시에 대해 자세하게 다루기엔 난이도가 높고 양도 많기 때문에 나중에 따로 글을 작성하겠습니다. 여기선 데이터 재배치 시에 데이터의 이동을 줄이기 위한 해싱 알고리즘이라고 이해하면 좋을 것 같습니다.
메시지 큐(Message Queues)
서비스를 하게 되면 실시간으로 해결하지 않아도 되는 작업들이 있습니다. 예를 들면 가입 환영 메일을 보내는 작업은 굳이 실시간으로 처리하지 않아도 될 겁니다. 이런 작업들은 동기적으로 처리하기보다 비동기적으로 처리하면 성능 면에서도 효과를 볼 수 있습니다. 이렇게 비동기로 처리하는 것을 도와주는 소프트웨어로 메시지 큐(Message Queues)가 있습니다. 메시지 큐는 발행자라 불리는 이벤트 발행 서비스가 이벤트를 생성하여 메시지 큐에 발행하면 구독자라 불리는 서비스에서 메시지를 받아 적절한 작업을 수행하도록 해줍니다. 이렇게 메시지 큐를 활용하여 비동기적으로 작업을 수행하게 되면 서비스간 결합이 느슨해진다는 장점이 있습니다.
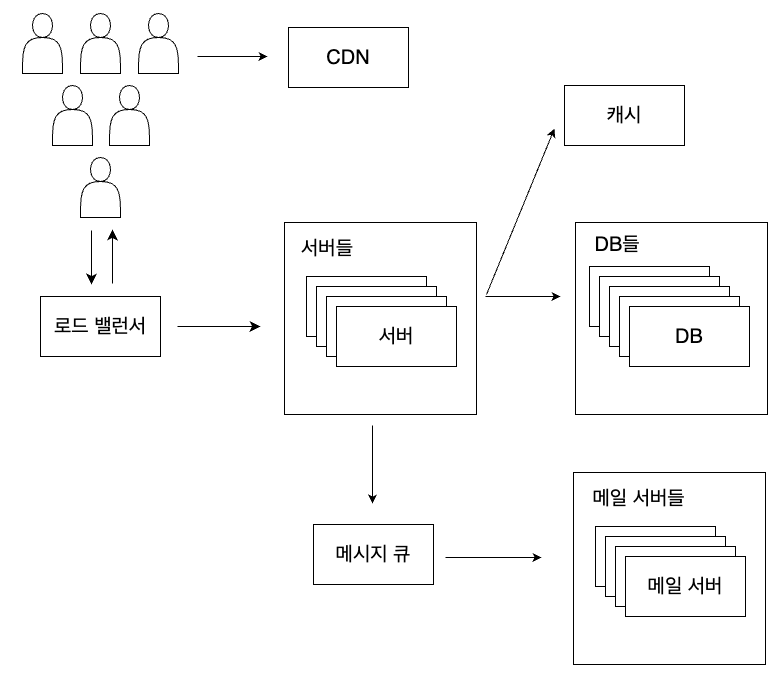
모니터링(Monitiring)
서비스를 하다보면 여러 상황이 발생할 수 있습니다. 장애가 발생하거나 성능이 떨어지거나 트래픽이 폭주하는 것처럼요. 그렇기에 현재 서비스의 상황을 빠르게 확인할 수 있어야 합니다. 이것이 모니터링(Monitoring)입니다. 모니터링 도구로는 대표적으로 Prometheus & Grafana, CloudWatch 등이 있습니다. 이때 모니터링하는 정보는 로그와 메트릭으로 나눌 수 있습니다.
- 로그 : 시스템에서 발생한 사건이나 요청 처리 과정 등을 텍스트의 형태로 기록한 것을 의미합니다.
- 메트릭 : 시스템의 상태나 성능을 수치화한 데이터 지표를 의미합니다.
이런 요소들을 모니터링하여 서비스의 상황을 실시간으로 확인하여 문제에 대응할 수 있도록 합니다. 이때 모니터링 도구나 서버들은 모니터링 결과가 모니터링에 드는 리소스에 영향을 받지 않도록 하기 위해 별도로 세팅해줍니다.
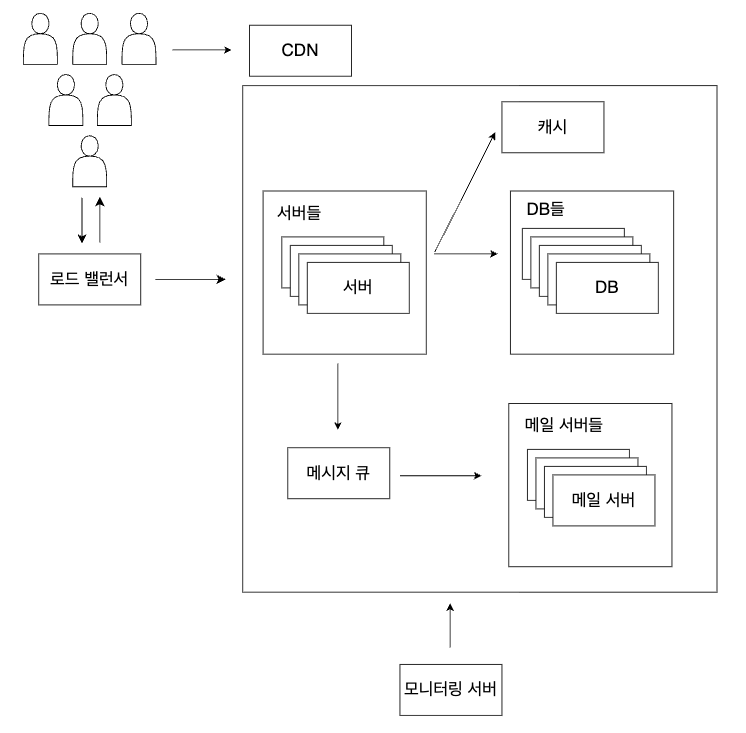
위협 대응
서비스를 하게 되면 보안이 매우 중요해집니다. 아무나 서비스를 마음대로 조작이 가능하면 개인정보가 유출되거나 마음대로 제어가 가능해지기 때문입니다. 그렇기 때문에 인증 및 인가(AuthN & AuthZ)가 필요합니다.
- 인증 : 사용자가 누구인지 확인하는 절차
- 인가 : 인증된 사용자가 해당 작업을 수행할 수 있는 권한이 있는 지 확인하는 절차
이 방식을 통해 사용자가 할 수 있는 작업들을 제한함으로써 보안을 향상시킬 수 있습니다.
또한 서비스가 받을 수 있는 공격에는 DDoS와 같은 공격도 있습니다. DDoS는 트래픽을 폭주시켜 서버를 마비시키는 행위입니다. 이런 공격을 예방하기 위해 요청 제한(Rate Limitiing)을 사용합니다. 요청 제한은 일정 시간동안 클라이언트의 요청 최대 개수를 제한하는 기술입니다. 이 기술을 통해 악성 트래픽을 차단하여 서버가 마비되는 상황을 예방할 수 있습니다.
마이크로서비스(Microservices)
일반적인 프로젝트는 대부분 각각의 서버가 서비스의 모든 작업을 처리할 수 있습니다. 이를 모노리틱 아키텍쳐라고 합니다. 하지만 서비스가 커지면서 작업이 많아지면 몇몇 문제가 발생할 수 있습니다. 여러 작업들 중 하나의 작업만 수정해서 배포할 때도 모든 작업 코드를 배포해야 됩니다. 또한 작업들 중 일부 작업에만 트래픽이 몰리는 경우 해당 작업에 대한 리소스만 확대하는 방식을 사용할 수 없습니다. 이런 상황에서 마이크로서비스(Microservices) 아키텍쳐가 나왔습니다. 모노리틱 아키텍쳐와 다르게 서비스를 서버 단위로 분할하여 하나의 서버가 하나의 서비스를 처리하는 방식입니다.
예를 들면 커뮤니티 기능, 상점 기능, 아바타 꾸미기 기능이 있는 서비스가 있다고 가정해보겠습니다. 모노리틱 아키텍쳐에서는 이 모든 기능이 하나의 서버에서 처리합니다. 하지만 마이크로서비스 아키텍쳐에서는 커뮤니티 기능을 처리하는 서버, 상점 기능을 처리하는 서버, 아바타 꾸미기 기능을 처리하는 서버가 별개로 운영됩니다. 이렇게 되면 각 기능별로 리소스를 다르게 할당할 수 있으며 하나의 기능에 문제가 발생했을 때 해당 기능만 배포하는 방식으로 처리할 수도 있습니다. 하지만 모든 방법에는 단점이 있듯이 마이크로서비스 아키텍쳐는 모노리틱 아키텍쳐에 비해 설계가 매우 복잡하다는 단점이 있습니다.
이렇게 마이크로서비스 아키텍쳐를 적용하게 되면 서로 연관된 기능이 있을 경우 각각의 서버별로 다른 서버의 api를 호출해야 되는 상황이 존재합니다. 그런데 각 기능 서버는 따로 배포가 가능하기 때문에 실시간으로 서버의 위치(IP/Port)가 변경될 수 있습니다. 그렇기에 다른 기능 서버를 사용하기 위해선 현재 해당 기능 서버의 위치를 알아야 되는데 이렇게 서버의 현재 위치를 알아내는 방법을 서비스 디스커버리(Service Discovery)라고 합니다.
서비스 디스커버리는 Service Registery를 활용합니다. Service Registery는 서비스 주소를 등록/조회하는 저장소입니다. 특정 기능 서버가 생성되면 해당 기능 서버의 이름과 주소를 Service Registery에 등록합니다. 이후에 다른 기능 서버에서 해당 기능을 사용하고 싶을 땐 Service Registery에서 해당 기능 서버의 위치를 조회해서 호출하게 됩니다.
또 이렇게 서비스가 여러개로 나뉘면 클라이언트의 경우 여러 서비스와 통신해야 할 수도 있습니다. 이는 복잡성, 지연, 보안과 같은 문제를 발생시킵니다. 이를 해결하기 위한 방법으로 API Gateway를 사용합니다. API Gateway는 리버스 프록시로 동작하면서 각 서비스에 대한 요청을 집계하고 그 응답을 결합하여 클라이언트에게 반환하거나 인증, 인가, 캐싱 등 클라이언트와 백엔드 간의 경계에서 이뤄지는 제어 로직을 수행합니다.
웹 소켓(WebSockets)
웹 소켓(WebSockets)은 클라이언트와 서버 간에 지속적인 연결을 유지하며 양방향 통신을 가능하게 하는 프로토콜입니다. 그래서 채팅이나 실시간 차트, 온라인 게임이나 알림 시스템 등 실시간성을 필요로 하는 기능에서 해당 프로토콜을 사용하게 됩니다.
참고자료
EP160: Top 20 System Design Concepts You Should Know
EP160: Top 20 System Design Concepts You Should Know
Load Balancing: Distributes traffic across multiple servers for reliability and availability.
blog.bytebytego.com
'System Architecture' 카테고리의 다른 글
| 엔지니어링의 트레이드오프: 실제 환경에서의 최종적 일관성 (Eventual Consistency) (0) | 2025.05.29 |
|---|---|
| Slack은 어떻게 하루 수십억 개의 메시지를 처리할까 (0) | 2025.05.22 |
| 마이크로서비스 설계 패턴 핵심 요약 (0) | 2025.05.10 |
| 당신이 알아야 할 시스템 설계의 핵심 개념 20가지 - 2. 캐싱 (0) | 2025.05.01 |
| 당신이 알아야 할 시스템 설계의 핵심 개념 20가지 - 1. 로드 밸런싱 (0) | 2025.05.01 |